What is Data fabric?

Data fabric is an end-to-end data integration and management solution, consisting of architecture, data management and integration software, and shared data that helps organizations manage their data. A data fabric provides a unified, consistent user experience and access to data for any member of an organization worldwide and in real-time.
Data fabric is designed to help organizations solve complex data problems and use cases by managing their data—regardless of the various kinds of applications, platforms, and locations where the data is stored. Data fabric enables frictionless access and data sharing in a distributed data environment.
Key characteristics of a Data Fabric typically include:
- Unified View: It offers a unified and consistent view of data assets across various locations and environments, providing a single point of access.
- Data Integration: Facilitates the integration of data from diverse sources and formats, enabling interoperability and data movement between systems.
- Data Orchestration: Supports automated data workflows and processes for efficient data management, including data movement, transformation, and synchronization.
- Scalability: Designed to scale horizontally and vertically to accommodate growing data volumes and diverse data types.
- Flexibility: Provides flexibility in deployment models, allowing organizations to leverage cloud, on-premises, and edge computing environments seamlessly.
- Data Security and Governance: Ensures consistent data governance policies and security measures across all data sources and locations to maintain data integrity and compliance.
- Real-time Access and Analytics: Enables real-time or near-real-time access to data for faster decision-making and actionable insights.
Data fabrics use technologies such as active metadata, knowledge graphs, semantics, and machine learning (ML) to augment data integration design and delivery. They can help businesses broaden access to data for a variety of use cases, including customer profiles, fraud detection, preventative maintenance analysis, and return-to-work risk models.
Data fabric benefits:
By automating metadata management, leaving data at the source, and providing a virtualized interface for different data sources, a data fabric delivers the benefits of centralization while empowering business units and individual data users. Automating routine workloads makes life easier for the central data team. They can focus on the higher-level responsibilities of fabric orchestration, such as defining semantics and metadata standards. Freed from more onerous tasks, the data teams become more accessible to business users. Even then, the data fabric reduces demand for data engineering by making company-wide data more consistent and accessible. Machine learning tools recommend datasets to streamline discovery. Integrating different datasets requires fewer and simpler data pipelines since the fabric guarantees semantic consistency and minimum data quality levels.
Data fabric architecture
By leveraging data services and APIs, data fabrics pull together data from legacy systems, data lakes, data warehouses, sql databases, and apps, providing a holistic view into business performance. In contrast to these individual data storage systems, it aims to create more fluidity across data environments, attempting to counteract the problem of data gravity—i.e., the idea that data becomes more difficult to move as it grows in size. A data fabric abstracts away the technological complexities engaged for data movement, transformation, and integration, making all data available across the enterprise.
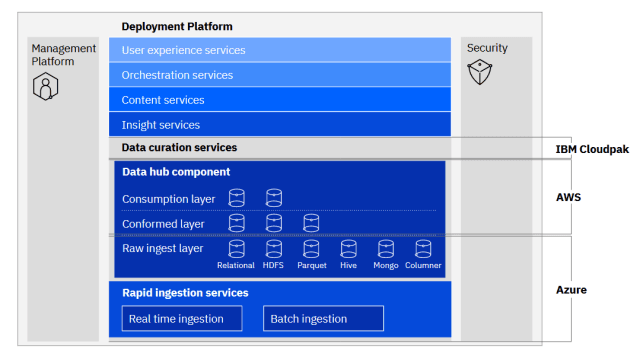
Data fabric architectures operate around the idea of loosely coupling data in platforms with applications that need it. One example of data fabric architecture in a multi-cloud environment may look like the below, where one cloud, like AWS, manages data ingestion and another platform, such as Azure, oversees data transformation and consumption. Then, you might have a third vendor, like IBM Cloud Pak® for Data, providing analytical services. The data fabric architecture stitches these environments together to create a unified view of data.
That said, this is just one example. There is not one single data architecture for a data fabric as different businesses have diverse needs. The various number of cloud providers and data infrastructure implementations ensure variation across businesses. However, businesses utilizing this type of data framework exhibit commonalities across their architectures, which are unique to a data fabric. More specifically, they have six fundamental components. These six layers include the following:
- Data Management layer: This is responsible for data governance and security of data.
- Data Ingestion Layer: This layer begins to stitch cloud data together, finding connections between structured and unstructured data.
- Data Processing: The data processing layer refines the data to ensure that only relevant data is surfaced for data extraction.
- Data Orchestration: This critical layer conducts some of the most important jobs for the data fabric—transforming, integrating, and cleansing the data, making it usable for teams across the business.
- Data Discovery: This layer surfaces new opportunities to integrate disparate data sources. For example, it might find ways to connect data in a supply chain data mart and customer relationship management data system, enabling new opportunities for product offers to clients or ways to improve customer satisfaction.
- Data Access: This layer allows for the consumption of data, ensuring the right permissions for certain teams to comply with government regulations. Additionally, this layer helps surface relevant data through the use of dashboards and other data visualization tools.
Storage infrastructure
Data fabric initiatives build upon the storage infrastructure and data management tools already in place. Nothing about how existing sources store and process data needs to change.
Moreover, companies do not need to migrate data into new repositories. Data can remain in place, whether that is a transactional database, a data warehouse, or a data lake.
Initially, this approach allows domains to retain control over their data sources. Eventually, datasets that support diverse use cases will become the central data team’s responsibility.
Advantages of data fabric architectures
As data fabric providers gain more adoption from businesses in the market, has noted specific improvements in efficiency, touting that it can reduce “time for integration design by 30%, deployment by 30%, and maintenance by 70%.” While data fabrics can improve overall productivity, the following benefits have also demonstrated business value for adopters:
- Intelligent integration: Data fabrics utilize semantic knowledge graphs, metadata management, and machine learning to unify data across various data types and endpoints. This aids data management teams in clustering related datasets together as well as integrating net new data sources into a business’s data ecosystem. This functionality automates aspects of data workload management, leading to the aforementioned efficiency gains, but it also helps to eliminate silos across data systems, centralize data governance practices, and improve overall data quality.
- Democratization of data: Data fabric architectures facilitate self-service applications, broadening the access of data beyond more technical resources, such as data engineers, developers, and data analytics teams. The reduction of data bottlenecks subsequently fosters more productivity, enabling business users to make faster business decisions and by freeing up technical users to prioritize tasks that better utilize their skillsets.
- Better data protection: The broadening of data access also does not mean compromising on data security and privacy measures. In fact, it means that more data governance guardrails are put into place around access controls, ensuring specific data is only available to certain roles. Data fabric architectures also allow technical and security teams to implement data masking and encryption around sensitive and proprietary data, mitigating risks around data sharing and system breaches.
Data virtualization and data fabric
Data virtualization creates a data fabric’s interface between architecture and analytics. Data resides in on-premises data centres and cloud data platforms but appears to users as a single enterprise data source.
Between its rich metadata, knowledge graphs, and recommendation engines, a data fabric makes it easier for users at various skill levels to access data. A self-service model lets analysts find the right data to support decision-makers using their existing business intelligence apps. Data scientists can count on the consistency between different data sources to reduce their data preparation workloads.
Implementation of data fabric
Data fabric begins with online transaction processing (OLTP) concepts. In online transactional processing, detailed information about every transaction is inserted, updated, and uploaded to a database. The data is structured, cleaned, and stored in silos at a centre for further usage. Any user of the data, at any point in the fabric, can take the raw data and use it to derive multiple findings, helping organizations leverage their data to grow, adapt, and improve.
Successful implementation of data fabric requires:
- Application and services: Where the necessary infrastructure for acquiring data is built. This includes development of apps and graphical user interfaces (GUIs) for the customer to interact with the organization.
- Ecosystem development and integration: Creating the necessary ecosystem for gathering, managing, and storing the data. Data from the customer needs to be transferred to the data manager and storage systems in a manner that avoids loss of data.
- Security: The data collected from all sources is to be managed with proper security.
- Storage management: Data is stored in an accessible and efficient manner, with an allowance to scale when required.
- Transport: Building the necessary infrastructure for accessing the data from any point in the organization’s geographic locations.
- Endpoints: Developing the software defined infrastructure at the storage and access points to allow insights in real time.
Use cases of data fabrics
Data fabrics are still in their infancy in terms of adoption, but their data integration capabilities aid businesses in data discovery, allowing them to take on a variety of use cases. While the use cases that a data fabric can handle may not be extremely different from other data products, it differentiates itself by the scope and scale that it can handle as it eliminates data silos. By integrating across various data sources, companies and their data scientists can create a holistic view of their customers, which has been particularly helpful with banking clients. Data fabrics have been more specifically used for:
- Customer profiles
- Fraud detection
- Preventative maintenance analysis
- Return-to-work risk models, and more.


How to handle geospatial data?

